1. VOCA: Voice Operated Character Animation

VOCA is a simple and generic speech-driven facial animation framework that works across a range of identities. This codebase demonstrates how to synthesize realistic character animations given an arbitrary speech signal and a static character mesh. For details please see the scientific publication
- Speech-driven facial animation: Speech based
- Text-driven facial animation: Text based
- Performance-based facial animation: Face landmarks based
간단히 말해서 음성(*.wav) 입력으로부터 입모양이 움직이는 3D Face Mesh(*.obj)를 만드는 방법이다.
현재까지나온 Lip-sync 관련 논문의 기초(Basis)에 해당하는 내용이라고 보면 된다.
이 논문은 발전해서 Facebook의 MeshTalk, Nvidia의 Audio2Face에 활용되고 있다.
1-1. MeshTalk(Facebook)
pretrained된 모델을 제공해주고 있으며 테스트해 볼 수 있다.
다만 학습 데이터를 아직 공개하고 있지 않아 추가 학습은 불가능하다.
1-2. Audio2Face(Nvidia)
현재 논문만 공개되어 있고 소스코드나 데이터는 제공되고 있지 않다.
Nvidia Omniverse(https://developer.nvidia.com/nvidia-omniverse-platform)를 설치하면 테스트 해볼 수 있다.
추후 감정도 반영하여 표정까지 움직이게 적용할 예정이라고 한다.
궁극적인 목표치에 도달하고 있는 듯한 결과물 (이직하고 싶다...!)
2. 논문: Capture, Learning, and Synthesis of 3D Speaking Styles
- 엄청난 양의 데이터와 딥러닝을 이용하여 음성과 얼굴 움직임간의 연관관계(many-to-many)를 파악
- 표정이 다양하게 변하지 않는 이유는 데이터 부족이 원인. 추가 학습을 통해 개선 가능
- Dataset: VOCASET (영상: 4D face scans, 60 fps, 29 min, 음성: 12 speackers, 480 sequences, 3~4 sec)
- DNN Model: VOCA (Voice Operated Character Animation)
- Languages: English, but supports Multi-language
- 활용 라이브러리: DeepSpeech, FLAME, (+ Mesh, RingNet)
* DeepSpeech 라이브러리 연동을 통한 음성 특징 추출
* FLAME 라이브러리 연동을 통한 애니메이션 기능 제공(머리, 턱, 눈, 형태 등 제어)
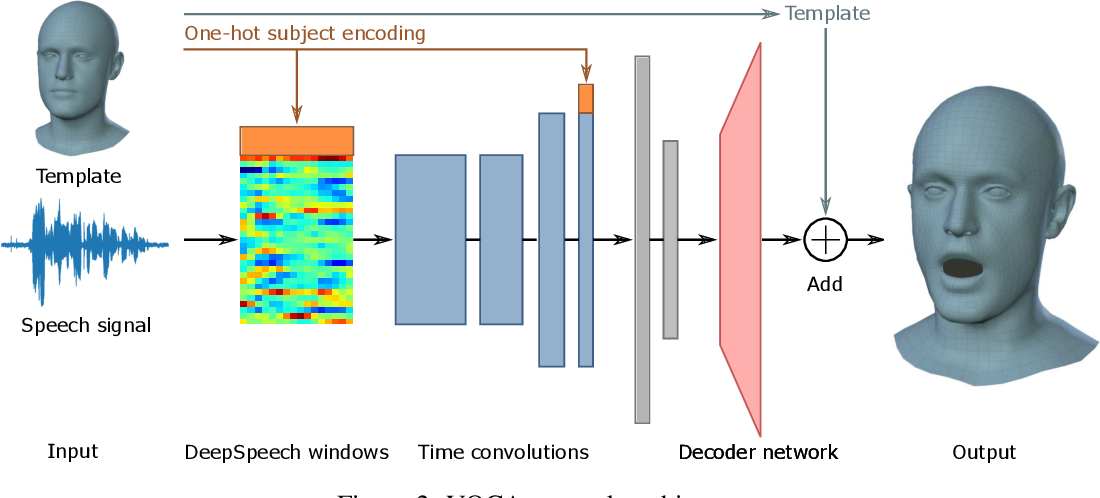
A. DeepSpeech windows
- Input: audio clip (T sec)
- Output: unnormalized log probabilites of characters (0.02 sec, 50 fps)
→ 50 * T * D
* D = 27 (# of alphabet and a blank)
B. Time convolutions (Encoder)
- Input: 60 * T * D * W
* W: window size
- Output: W * 1 * (D + 8)
C. Decoder network
- Output: 5023 * 3 (x, y, z)
